Проекти
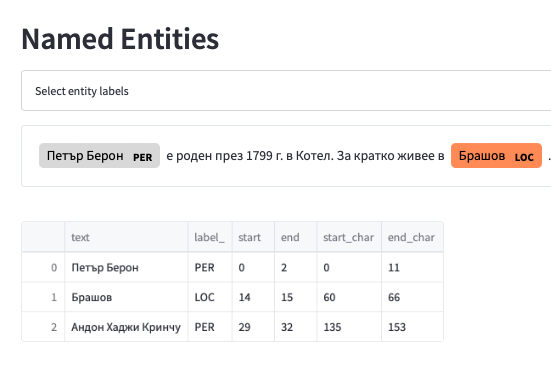
Bulgarian spaCy models
Български spaCy модели за анализ на текст, тренирани върху корпус от медийни текстове - токенизация, лематизация, разпознаване на части на речта (POS tagger), граматичен, морфологичен и синтактичен анализ, Named Entity Recognition (NER)
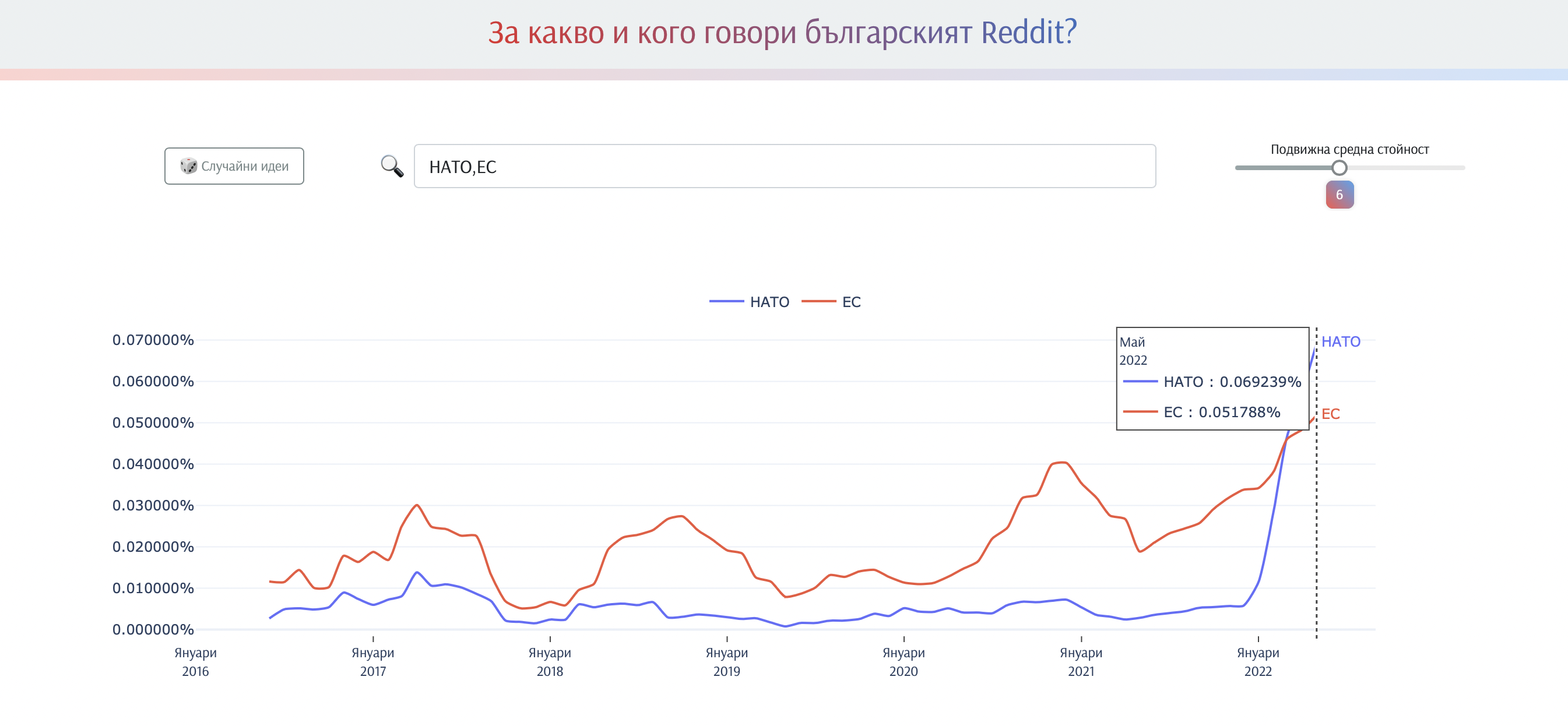
Bulgarian Reddit Ngram Viewer
Приложение за визуализиране на различни фрази и думи (N-грами), извлечени от коментарите и постовете на българското Reddit пространство — ([r/bulgaria](https://www.reddit.com/r/bulgaria/))

Writing assistant
Малко приложение, което автоматизира някои граматически правила, които не са лесно достъпни на фонетичната клавиатура на Windows или пък са често пренебрегвани. Създадох го за приятелката ми, за да ѝ спестява време при писането на прессъобщения.
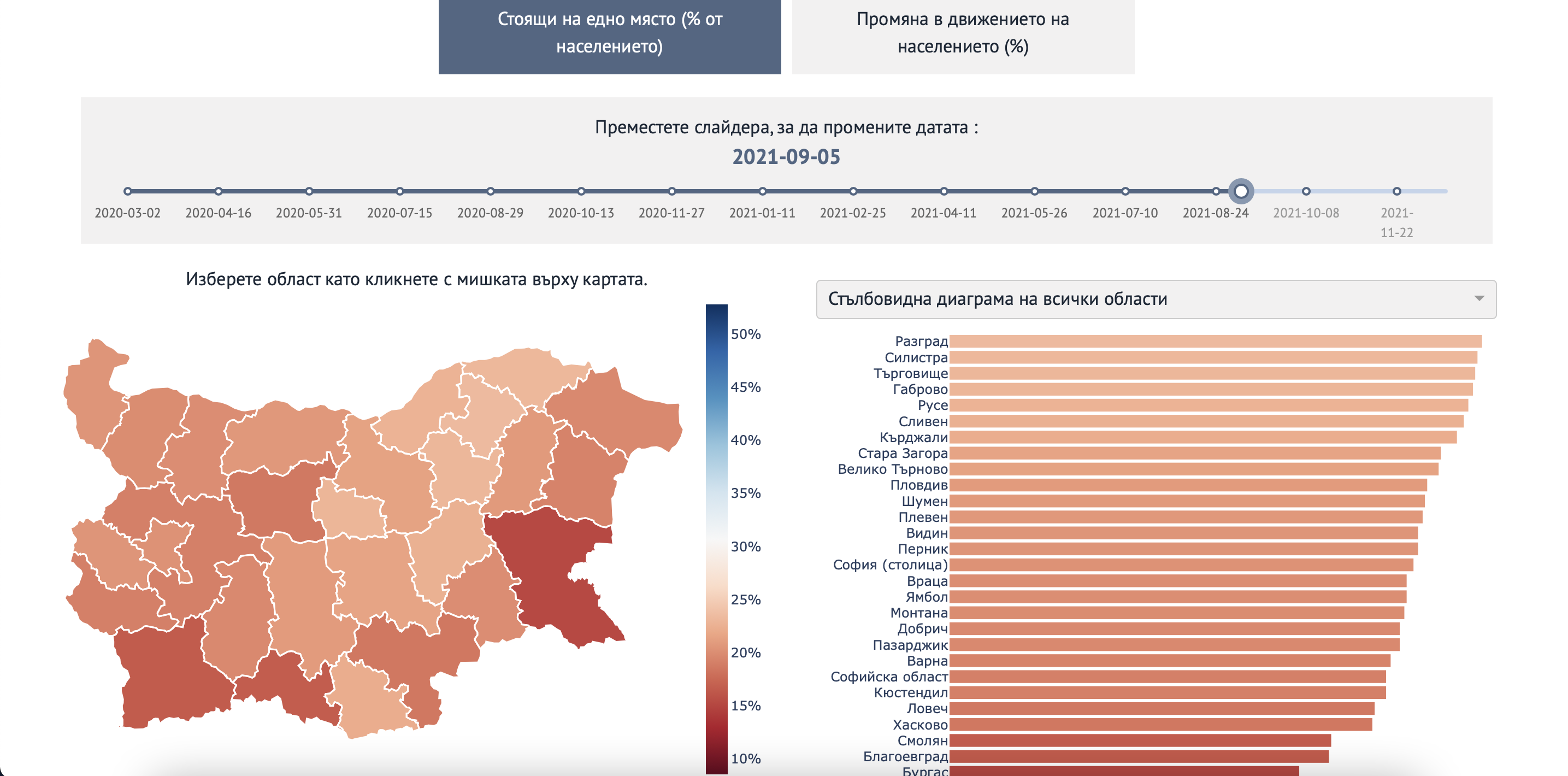
Движение на хората в България по време на Covid-19
Уебсайт който визуализира трендовете на движение на хората в България от началото на епидемията.